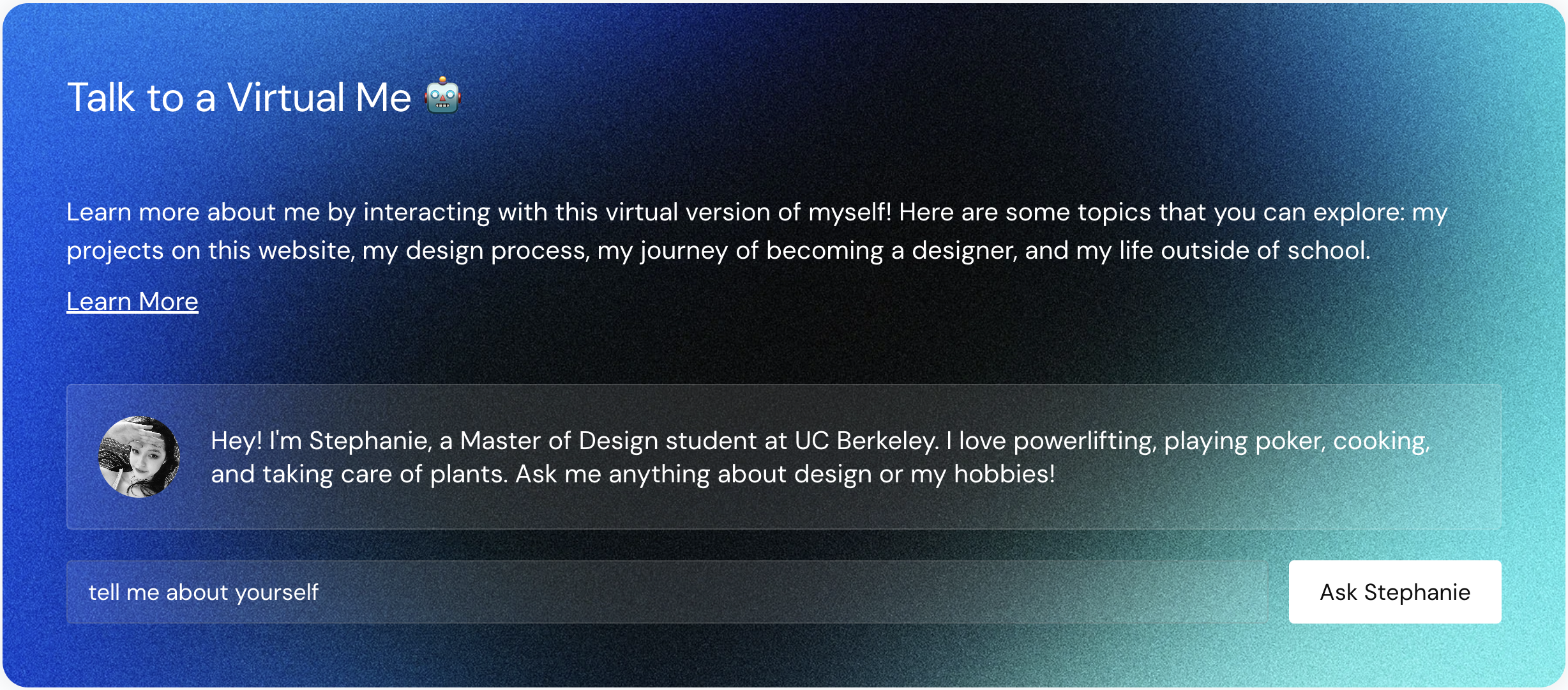
Talk to a virtual me
Designing a virtual human assistant that provides a smooth meal ordering experience for hospital patients.

A note from Stephanie:
This project is no longer actively maintained, so unfortunately you cannot give it a try :(
I originally wanted to write more about the implementation details, but I realized that much of the tech now feels surprisingly stale — almost like something from a decade ago, even though it has only been three years. Still, it feels nostalgic to look back on this project and remember a time when I genuinely thought that “making my own chatbot” meant training a model on my own data.
I went back and forth with ChatGPT for days until I finally figured out how to make it work. Today, the same thing would probably take less than 10 minutes. Good old times.
Design
Finetuning and contextual retrival
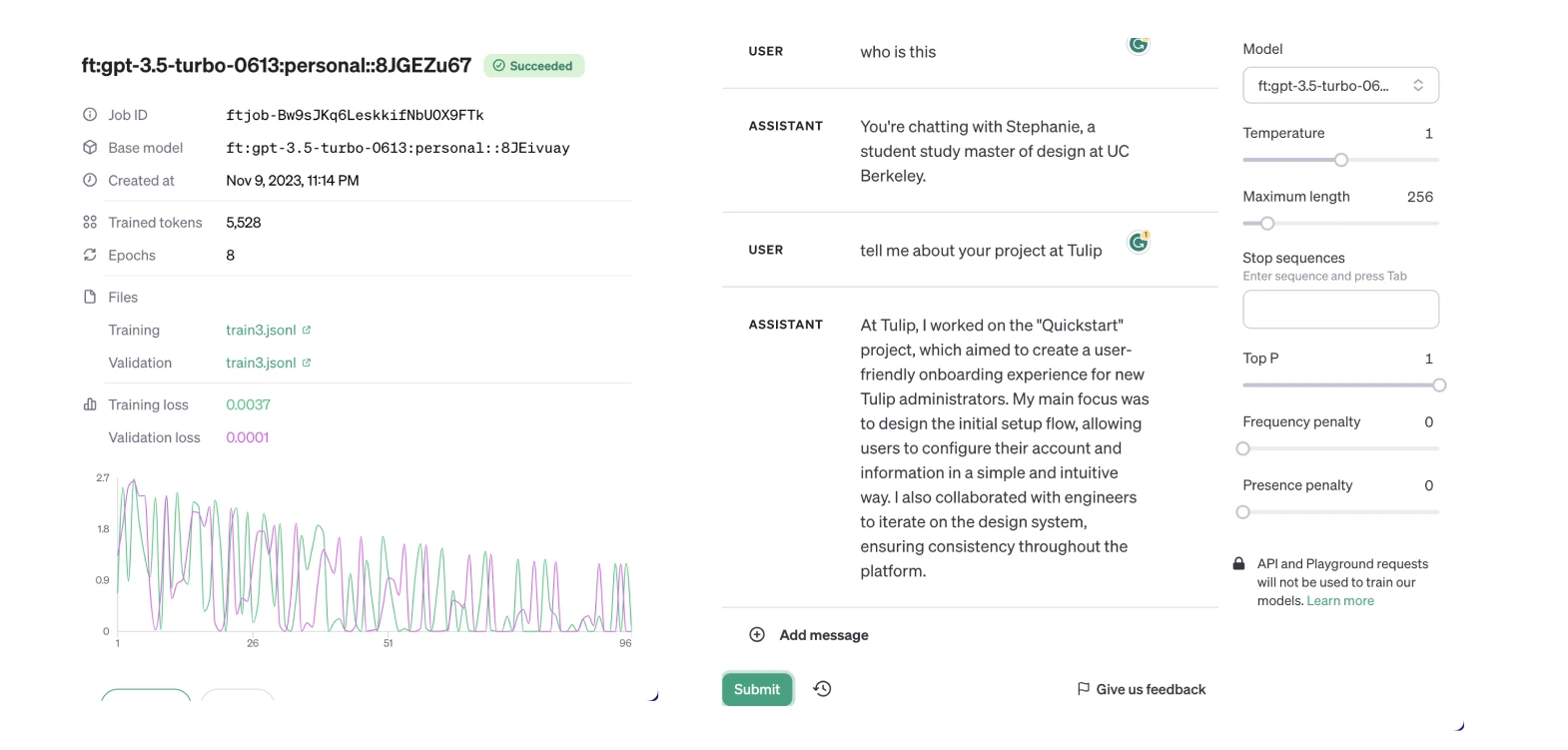
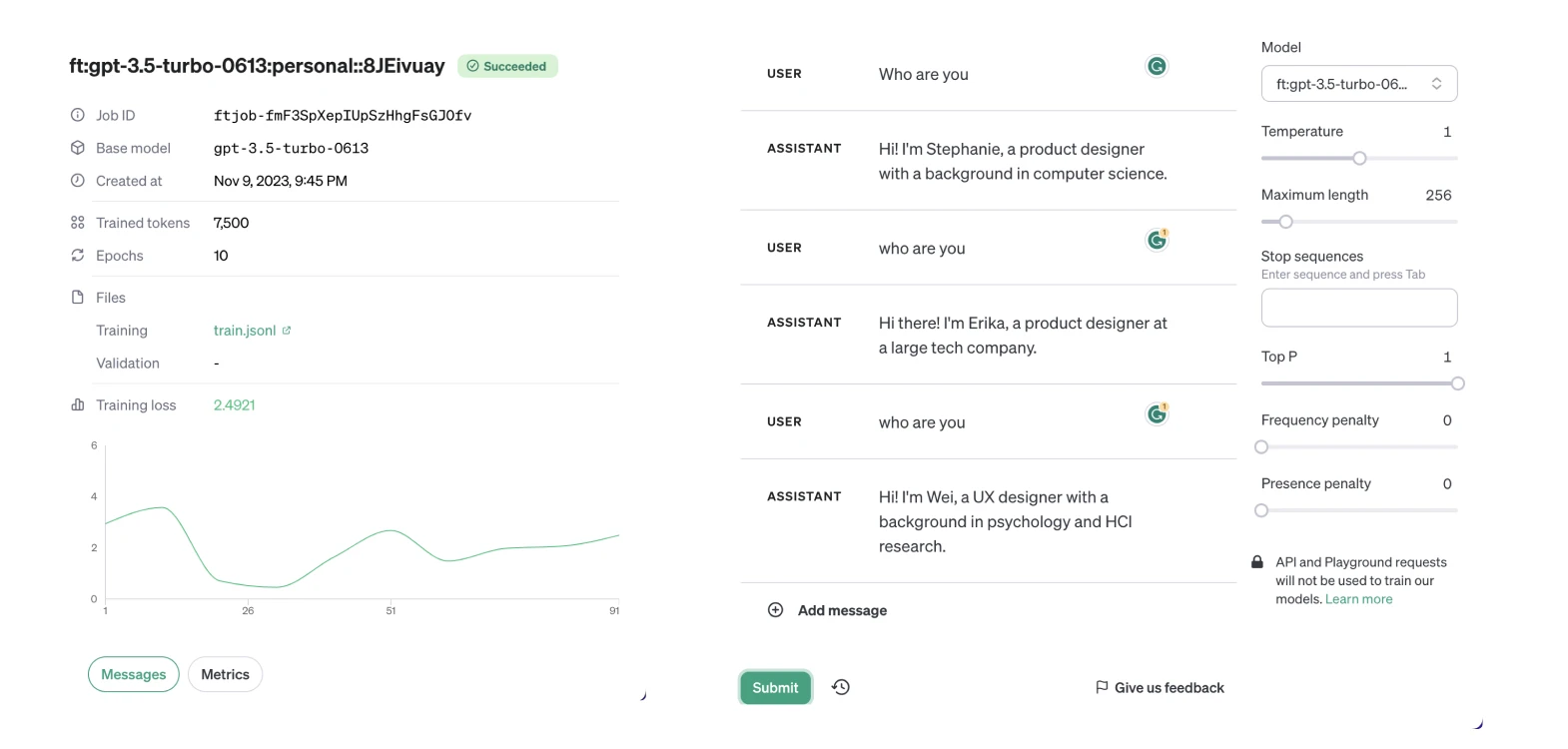
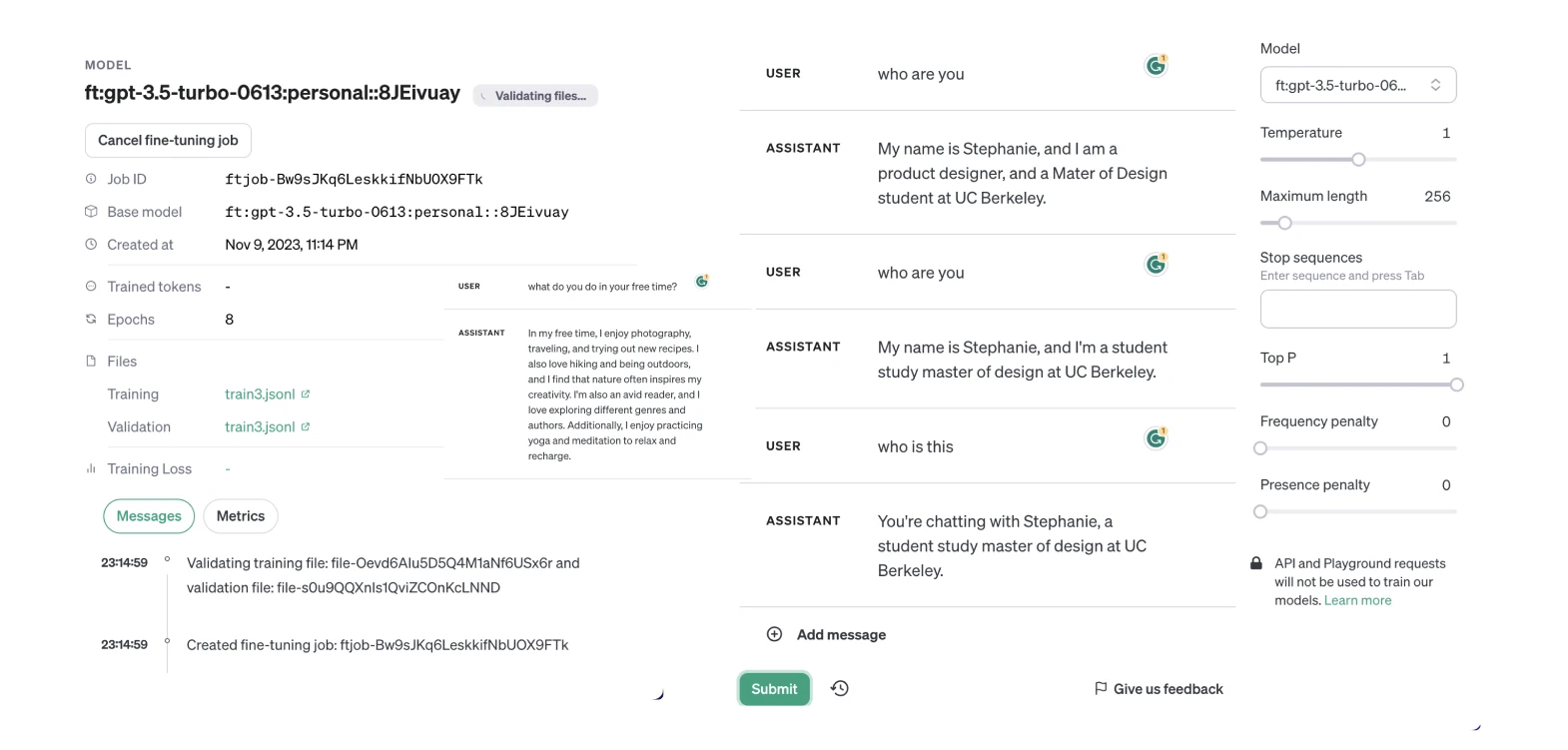
During the fine-tuning process project, I did more research and realized that while fine-tuning the GPT-3.5 turbo model was initially promising, it was not the most cost-effective or efficient approach for my needs. The process of fine-tuning required extensive data preparation (more than 500 lines) and iterative training, which resulted in significant computational expense and time investment.
As I delved deeper, it became evident that enhancing the model's performance could be more effectively achieved by focusing on the front end. Instead of fine-tuning, I shifted my strategy to layer in additional context within the front-end application. This method allowed the virtual assistant to access relevant information in real-time, improving its accuracy and the relevance of its responses without the overhead of continuously training the model.
As I delved deeper, it became evident that enhancing the model's performance could be more effectively achieved by focusing on the front end. Instead of fine-tuning, I shifted my strategy to layer in additional context within the front-end application. This method allowed the virtual assistant to access relevant information in real-time, improving its accuracy and the relevance of its responses without the overhead of continuously training the model.
Talk to a virtual me
Built Stephanie’s bot in 2023, the pre-claude code/codex era. I played around with model fine tuning and contextual retrieval before everyone started to bring a chatbot into their personal websites.

A note from Stephanie:
This project is no longer actively maintained, so unfortunately you cannot give it a try :(
I originally wanted to write more about the implementation details, but I realized that much of the tech now feels surprisingly stale — almost like something from a decade ago, even though it has only been three years. Still, it feels nostalgic to look back on this project and remember a time when I genuinely thought that “making my own chatbot” meant training a model on my own data.
I went back and forth with ChatGPT for days until I finally figured out how to make it work. Today, the same thing would probably take less than 10 minutes. Good old times.
Design
Fine-tuning? Contextual retrieval?
During the fine-tuning process project, I did more research and realized that while fine-tuning the GPT-3.5 turbo model was initially promising, it was not the most cost-effective or efficient approach for my needs. The process of fine-tuning required extensive data preparation (more than 500 lines) and iterative training, which resulted in significant computational expense and time investment.
As I delved deeper, it became evident that enhancing the model's performance could be more effectively achieved by focusing on the front end. Instead of fine-tuning, I shifted my strategy to layer in additional context within the front-end application. This method allowed the virtual assistant to access relevant information in real-time, improving its accuracy and the relevance of its responses without the overhead of continuously training the model.